08:50 Научные интернет-публикации в файлах в поиске Яндекса и Гугла |
|
В начале этого года на сайте был размещён пост о плюсах и минусах публикациях в файлах. Этот материал вызвал небольшую дискуссию с пользователем alivan (довольно частый и всегда желанный гость на сайте; знаю, что он мой коллега-преподаватель, знаю, как его зовут, но здесь ограничусь ником). Суть дискуссии: как будет ранжироваться в выдаче оригинальная научная статья, опубликованная в файле, если с ней начнут конкурировать её копии, которые потом появятся на других сайтах. Кое-что из наших рассуждений есть в комментариях к тому посту, а большей частью аргументов и гипотез мы обменялись в личной переписке. Выяснилось, что нас обоих это заинтересовало, но мы не владеем точно установленными фактами, чтобы утверждать что-либо определённо. Теперь некоторые факты имеются. Я изучил позиции в поисковой выдаче нескольких статей, опубликованных в файлах в феврале-апреле 2013 года и растиражированных, минимум, тремя разными сайтами. Для примера возьму одну из публикаций, чьи позиции в поисковых выдачах в целом отражают общую картину. Сначала вводная информация. 1. Точно известно, что… - статья Ольги Сергеевны Иониной «Тренинг как средство развития эмпатических способностей педагога» впервые в Интернете была опубликована на vestnikkaf.esrae.ru (мы с Ольгой Сергеевной коллеги, хорошо знакомы, и я вхожу в состав редколлегии этого сетевого издания); - вскоре после публикации копия статьи в формате pdf была выложена мной на sv-sidorov.ucoz.com – старой версии моего сайта – разумеется, со ссылкой на vestnikkaf.esrae.ru на странице загрузки (не с тестовой целью – тогда я об этом не думал, просто хотел заинтересовать своих посетителей недавно созданным научным журналом). 2. Предполагалось, что обязательно найдётся ещё какой-нибудь ресурс, который продублирует статью пресловутым «методом генерации текстов». 3. Используя название статьи в качестве поискового запроса, посмотрим, как влияет на выдачу ведущих поисковиков наличие, минимум, трёх одноимённых и идентичных по основному содержанию страниц, отличающихся лишь форматом файлов и разметкой страниц. Поисковый запрос – тренинг как средство развития эмпатических способностей педагога – не просто низкочастотный, он уникален, поскольку это название уникальной авторской статьи. К тому же статья научная, она вызовет интерес у сравнительно небольшой группы специалистов. Это означает, что её, всего скорей, не будут массово копировать и распространять в сети Интернет, а при небольшом количестве копий нам в них будет проще разобраться. В общем, так и есть: в первой десятке выдач Яндекса и Гугла всего по три ссылки, имеющих отношение именно к этой статье (см. картинки-скриншоты). Топ-10 выдачи Google (фрагмент) 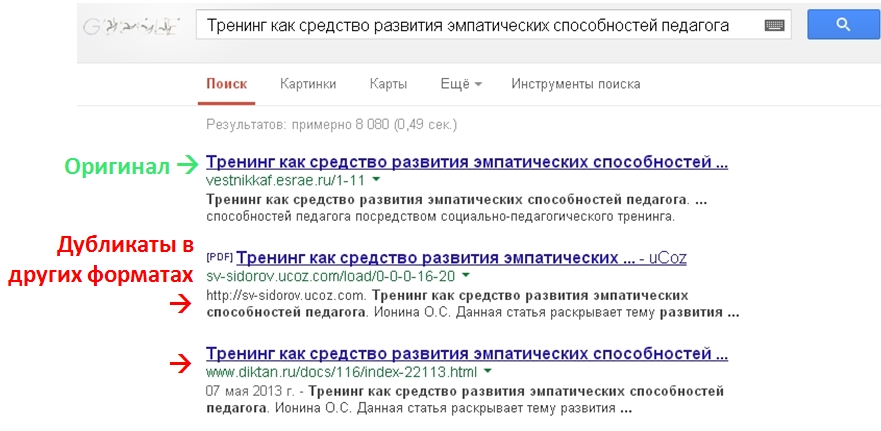 Топ-10 выдачи Яндекса (фрагмент) 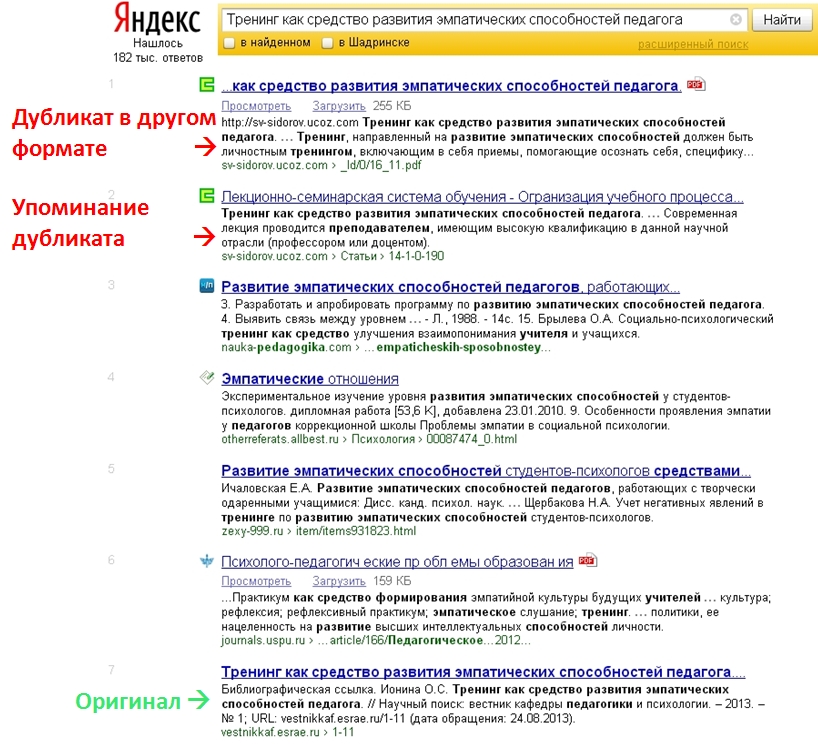 Первое, что бросается в глаза при сравнении выдач Яндекса и Гугла, это значительный разброс позиций. Выдача Гугла выглядит более корректно: 1-я позиция – первоисточник в формате doc; 2-е место – корректная «ручная» копия в формате pdf на моём сайте; 3-е место – явно автоматически сгенерированная страница html.Далее идут страницы с названиями, отличными от поискового запроса (я обрезал скриншот сразу после 3-й позиции, но поверьте, что это так). Однако обратите внимание на сниппеты (коротенькие описания рядом с основными ссылками). Именно в ссылках на копии статьи сниппеты наиболее корректны, так как содержат ФИО автора и название статьи. Поэтому очень высока вероятность, что пользователь, ищущий научную публикацию, кликнет не первую, а вторую или третью ссылку. Яндекс явно учёл «авторитетность», «трастовость» сайтов, и на 1-е место поставил мою страницу в формате pdf (это загружаемый файл со статьёй, название которой полностью соответствует поисковому запросу). На 2-м месте почему-то тоже моя страница, но совершенно другой тематики: текст, соответствующий названию разыскиваемой статьи там оказался случайно, это одна из многих внутренних ссылок. Видимо, Яндекс посчитал мой сайт старше и «солидней». Страница-первоисточник на молодом ресурсе vestnikkaf.esrae.ru отброшена на 7-е место, а промежуток между 1-м и 7-м местами заполнили страницы с другими названиями. Зато сниппет к ссылке на первоисточник у Яндекса просто идеален для библиографического поиска: это корректное библиографическое описание. Но дойдёт ли пользователь до 7-й позиции в выдаче, найдя нужную статью в первой же ссылке – это ещё вопрос. Сайтов, пополняющихся за счёт создания веб-страниц из чужих текстов, в первой десятке выдачи Яндекса не наблюдается, и это радует. В чём Яндекс и Гугл оказались единодушны, так это в стремлении к разнообразию. Оба из разных интернет-источников выбрали страницы, отличающиеся по структуре и формату. Например, они поставили в выдачу не только страницы загрузки, но и сами загружаемые файлы. Тем самым поисковики максимально учли интересы пользователя. Интересы автора в данном случае тоже не пострадали (если не считать того, что при цитировании кем-либо данной работы может быть указан не первоисточник – электронный журнал научных публикаций – а какой-либо другой сайт). Однако заслуга в этом не столько поисковиков, сколько тех, кто корректно указал сведения об авторе и источнике на страницах, содержащих скопированный текст. 12.09.2013. Для ссылки: Научные интернет-публикации в файлах в поиске Яндекса и Гугла [Электронный ресурс] // Сидоров С.В. Педагог-исследователь – URL: http://si-sv.com/blog/2013-09-12-56 (дата обращения: 21.07.2026). |
|
|
| Всего комментариев: 7 | |
|
| |

 Не заводить же мне отдельный аккаунт Google+ для каждого автора, соавтора.
Не заводить же мне отдельный аккаунт Google+ для каждого автора, соавтора. 